MagicDrive: Street View Generation with Diverse 3D Geometry Control
Recent advancements in diffusion models have significantly enhanced the data synthesis with 2D control. Yet, precise 3D control in street view generation, crucial for 3D perception tasks, remains elusive. Specifically, utilizing Bird's-Eye View (BEV) as th
arxiv.org
Project Page: https://gaoruiyuan.com/magicdrive/
MagicDrive: Street View Generation with Diverse 3D Geometry Control
Recent advancements in diffusion models have shown remarkable promise in data synthesis, enhancing a wide range of 2D perception tasks. However, achieving precise control in street view generation for 3D perception tasks still remains a formidable challeng
gaoruiyuan.com
공식 코드 저장소: https://github.com/cure-lab/MagicDrive
GitHub - cure-lab/MagicDrive: [ICLR24] Official implementation of the paper “MagicDrive: Street View Generation with Diverse 3
[ICLR24] Official implementation of the paper “MagicDrive: Street View Generation with Diverse 3D Geometry Control” - cure-lab/MagicDrive
github.com
ABSTRACT
Recent advancements in diffusion models have significantly enhanced the data synthesis with 2D control. Yet, precise 3D control in street view generation, crucial for 3D perception tasks, remains elusive. Specifically, utilizing Bird’s-Eye View (BEV) as the primary condition often leads to challenges in geometry control (e.g., height), affecting the representation of object shapes, occlusion patterns, and road surface elevations, all of which are essential to perception data synthesis, especially for 3D object detection tasks. In this paper, we introduce MAGICDRIVE, a novel street view generation framework, offering diverse 3D geometry controls including camera poses, road maps, and 3D bounding boxes, together with textual descriptions, achieved through tailored encoding strategies. Besides, our design incorporates a cross-view attention module, ensuring consistency across multiple camera views. With MAGICDRIVE, we achieve high-fidelity street-view image & video synthesis that captures nuanced 3D geometry and various scene descriptions, enhancing tasks like BEV segmentation and 3D object detection.
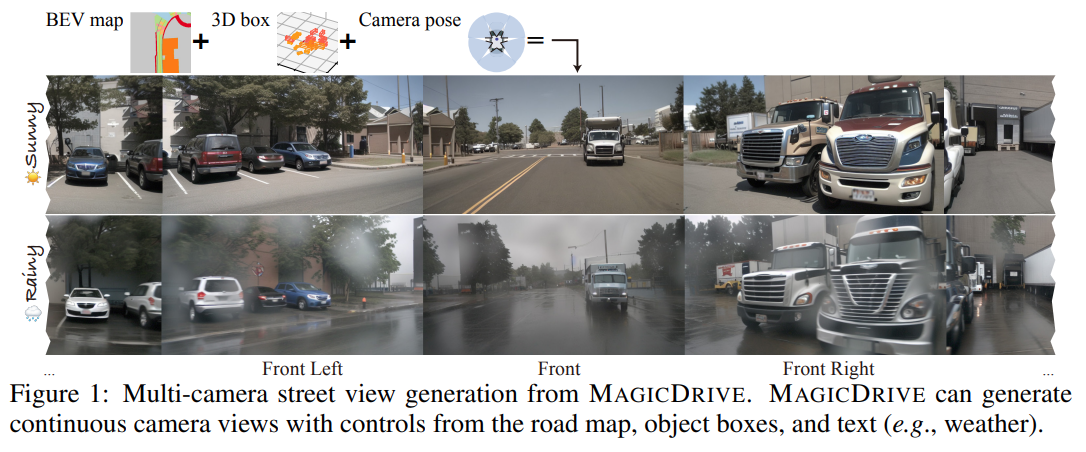

For street-view data synthesis, two pivotal criteria are realism and controllability. Realism requires that the quality of the synthetic data should align with that of real data; and in a given scene, views from varying camera perspectives should remain consistent with one another (Mildenhall et al., 2020). On the other hand, controllability emphasizes the precision in generating street-view images that adhere to provided conditions: the BEV map, 3D object bounding boxes, and camera poses for views. Beyond these core requirements, effective data augmentation should also grant the flexibility to tweak finer scenario attributes, such as prevailing weather conditions or the time of day.
The rise of diffusion models has significantly pushed the boundaries of controllable image generation quality. Specifically, ControlNet (Zhang et al., 2023a) proposes a flexible framework to incorporate 2D spatial controls based on pre-trained Text-to-Image (T2I) diffusion models (Rombach et al., 2022). However, 3D conditions are distinct from pixel-level conditions or text. The challenge of seamlessly integrating them with multi-camera view consistency in street view synthesis remains.
In this paper, we introduce MAGICDRIVE, a novel framework dedicated to street-view synthesis with diverse 3D geometry controls1 . For realism, we harness the power of pre-trained stable diffusion (Rombach et al., 2022), further fine-tuning it for street view generation. One distinctive component of our framework is the cross-view attention module. This simple yet effective component provides multi-view consistency through interactions between adjacent views. In contrast to previous methods, MAGICDRIVE proposes a separate design for objects and road map encoding to improve controllability with 3D data. More specifically, given the sequence-like, variable-length nature of 3D bounding boxes, we employ cross-attention akin to text embeddings for their encoding. Besides, we propose that an addictive encoder branch like ControlNet (Zhang et al., 2023a) can encode maps in BEV and is capable of view transformation. Therefore, our design achieves geometric controls without resorting to any explicit geometric transformations or imposing geometric constraints on multi-camera consistency. Finally, MAGICDRIVE factors in textual descriptions, offering attribute control such as weather conditions and time of day.
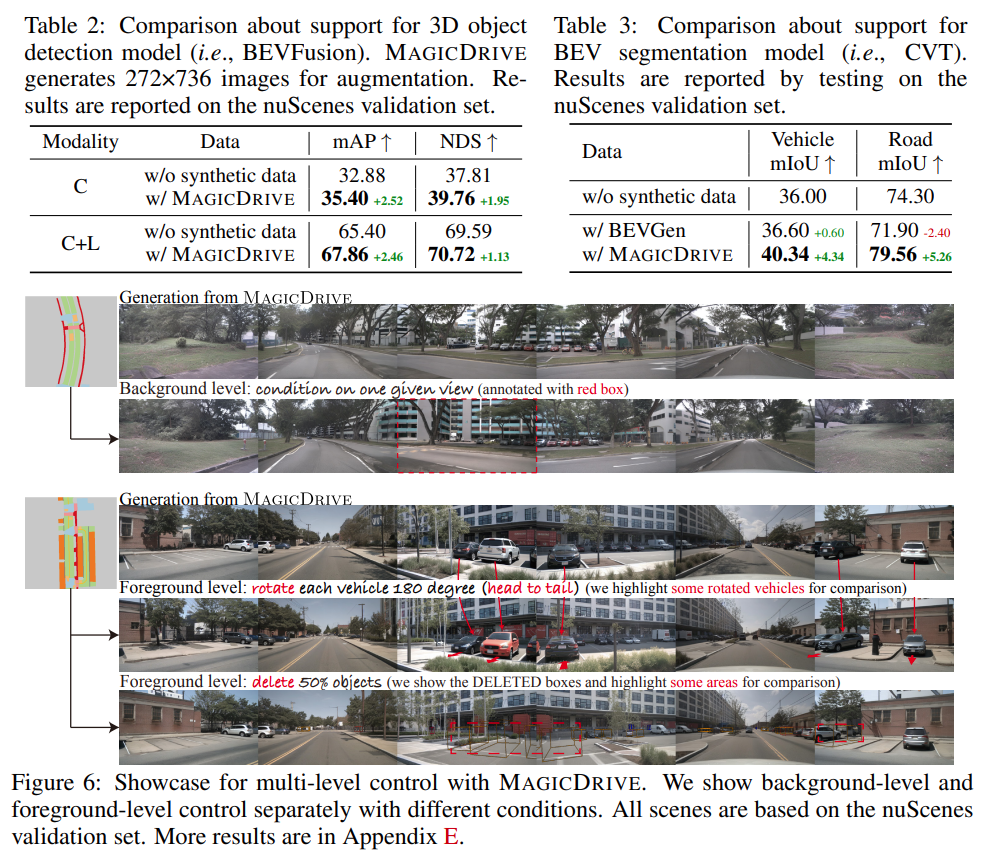
Our MAGICDRIVE framework, despite its simplicity, excels in generating strikingly realistic images & videos that align with road maps, 3D bounding boxes, and varied camera perspectives. Besides, the images produced can enhance the training for both 3D object detection and BEV segmentation tasks. Furthermore, MAGICDRIVE offers comprehensive geometric controls at the scene, background, and foreground levels. This flexibility makes it possible to craft previously unseen street views suitable for simulation purposes. We summarize the main contributions of this work as:
- The introduction of MAGICDRIVE, an innovative framework that generates multi-perspective camera views & videos conditioned on BEV and 3D data tailored for autonomous driving.
- The development of simple yet potent strategies to manage 3D geometric data, effectively addressing the challenges of multi-camera view consistency in street view generation.
- 이를 위해, Geometric Condutuins Encoding (4.1절), Cross-view Attention (4.2절) 을 제안함
- Geometric Condutuins Encoding
- Scene-level Encoding (CLIP text encoder 사용)
+ 3D Bounding Box Encoding
+ Road Map Encoding (2d grid map 사용, 학습에 필수적 X, optional)
- Scene-level Encoding (CLIP text encoder 사용)
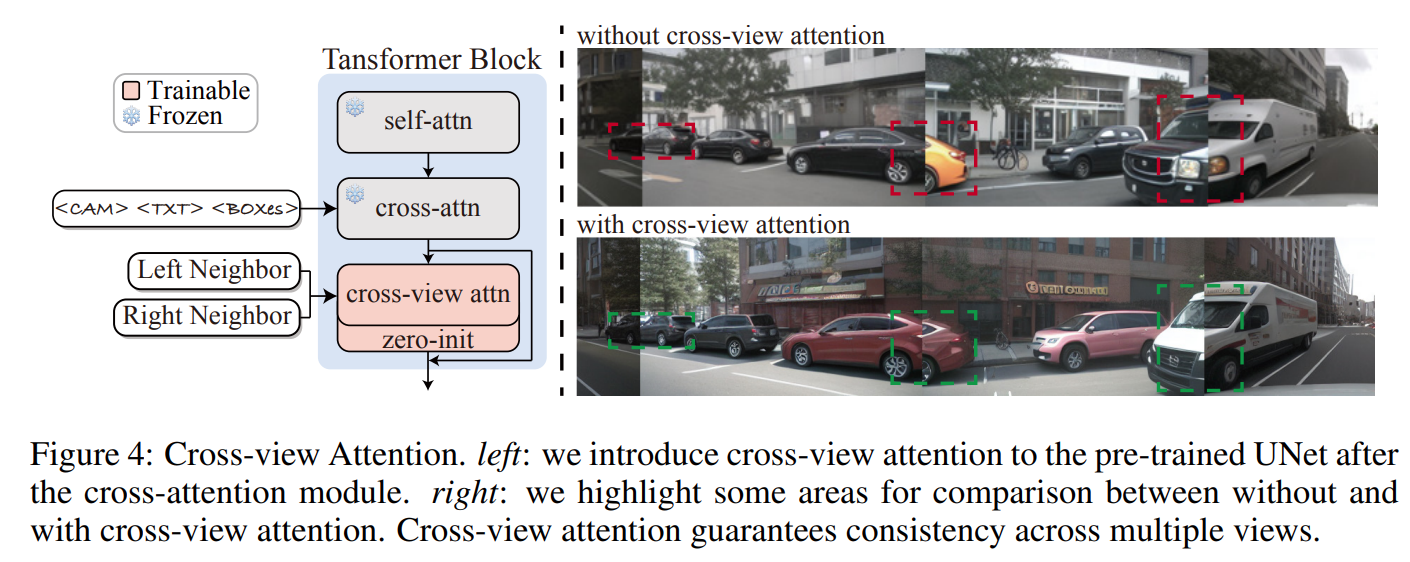
- Cross-view Attention
- We inject cross-view attention after the cross-attention module in the UNet and apply zero initialization (Zhang et al., 2023a) to bootstrap the optimization.
- 인접한 두개의 view 화면 간 cross-view attention 수행
- cross-attention -> cross-view attention -> zero initialization 적용
- We inject cross-view attention after the cross-attention module in the UNet and apply zero initialization (Zhang et al., 2023a) to bootstrap the optimization.
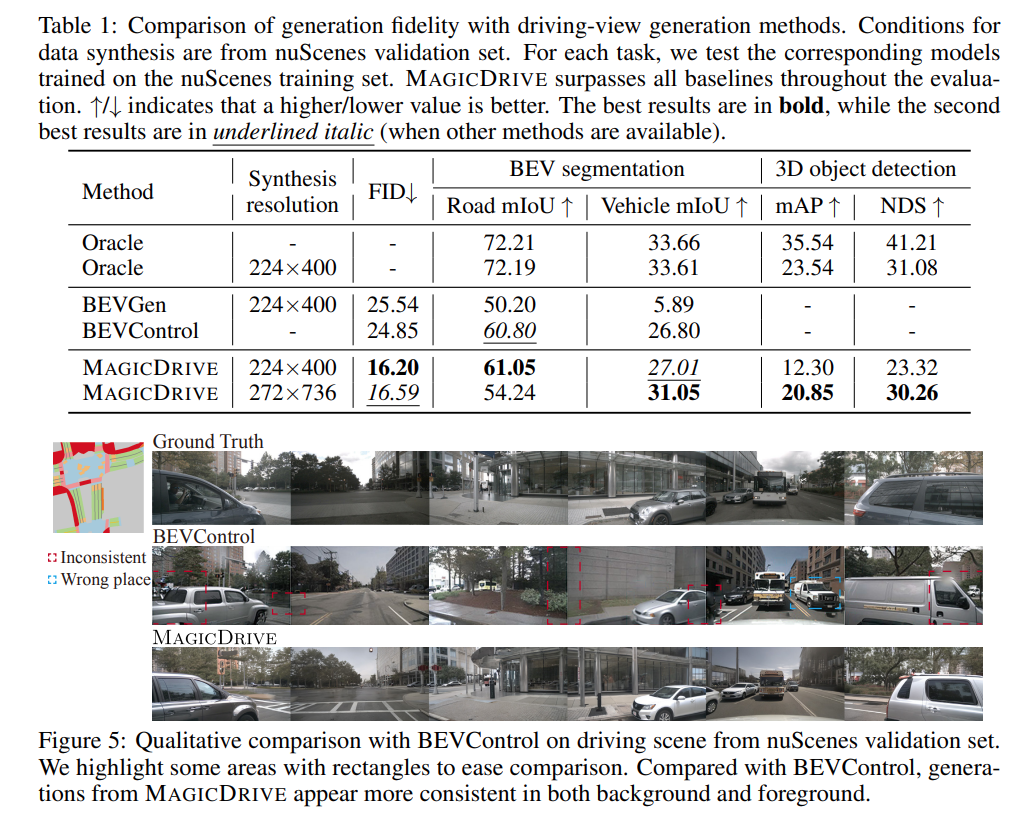
- Through rigorous experiments, we demonstrate that MAGICDRIVE outperforms prior street view generation techniques, notably for the multi-dimensional controllability. Additionally, our results reveal that synthetic data delivers considerable improvements in 3D perception tasks.

MODEL 학습 시, 아래 두개 테크닉 적용
- Classifier-Free Guidance (CFG)
- Training Objective and Augmentation
**Classifier-Free Guidance (CFG)**는 텍스트-조건 생성 모델(Text-to-Image 또는 Text-to-Text)에서 샘플 품질과 다양성을 조절하기 위한 테크닉입니다. 딥러닝 기반 생성 모델에서, 특히 Denoising Diffusion Models나 Stable Diffusion 같은 모델에서 많이 사용됨
주요 아이디어:
1. Conditioned와 Unconditioned Sampling의 조합
- Conditioned Sampling: 입력 텍스트(프롬프트)에 따라 모델이 특정한 방향으로 샘플을 생성함
- Unconditioned Sampling: 입력 텍스트 없이, 즉 아무 조건 없이 모델이 자유롭게 샘플을 생성함
CFG는 이 두 가지를 적절히 섞어서 생성 결과를 조정함
2. 수식
생성 과정에서 x_t라는 상태(예: 노이즈 단계)에서 다음 상태를 예측할 때

3. 결과 해석
- : 텍스트 조건에 더 집중한 샘플을 생성 (더 선명하거나 의도에 가까운 결과).
- : 일반적인 샘플링.
- : 텍스트 조건의 영향을 줄이고 더 자유로운 샘플을 생성.
장점
- 더 나은 품질의 생성물: 조건(텍스트 프롬프트)에 대한 응답성이 높아져 더 정확한 이미지를 생성할 수 있음.
- 더 다양한 결과: 값을 낮추면 다양성을 증가시키며, 높이면 더 정교하고 의도된 결과를 얻음.
사용 사례
- Stable Diffusion, DALL-E: 텍스트 프롬프트로 이미지를 생성할 때 CFG를 사용해 세부 묘사를 강화.
- Language Models: 텍스트 생성 모델에서 프롬프트에 따른 정확성을 높이기 위해 활용.
- Denoising Diffusion Models: 노이즈를 제거하면서 조건에 따른 세부 묘사를 조정.
간단히 말하면, Classifier-Free Guidance는 모델이 텍스트 조건을 얼마나 따를지를 조정하는 기술로, 품질과 창의성 사이에서 균형을 맞추는 데 중요한 역할을 한다고 함.
<< 참고 문헌 >>
- https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/ldm/
- https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/cfdg/
[논문리뷰] Classifier-Free Diffusion Guidance
Classifier-Free Diffusion Guidance 논문 리뷰 (NeurIPS Workshop 2021)
kimjy99.github.io
[논문리뷰] High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
Stable Diffusion 논문 리뷰 (CVPR 2022)
kimjy99.github.io
이 논문에서 사용된 "Training Objective and Augmentation"
With all the conditions injected as inputs, we adapt the training objective described in Section 3 to the multi-condition scenario, as in Equation 9.
| ℓ=𝔼𝒙0,𝜖,𝑡,{𝑺,𝑷}[‖𝜖−𝜖𝜃(𝛼¯𝑡ℰ(𝒙0)+1−𝛼¯𝑡𝜖,𝑡,{𝐒,𝐏})‖]. | (9) |
Besides, we emphasize two essential strategies when training our MagicDrive. First, to counteract our filtering of visible boxes, we randomly add 10% invisible boxes as an augmentation, enhancing the model’s geometric transformation capabilities. Second, to leverage cross-view attention, which facilitates information sharing across multiple views, we apply unique noises to different views in each training step, preventing trivial solutions to Equation 9 (e.g., outputting the shared component across different views). Identical random noise is reserved exclusively for inference.
모든 조건을 입력으로 주입하면, 섹션 3에 설명된 훈련 목표를 방정식 9와 같이 다중 조건 시나리오에 맞게 조정함
<< 섹션 3의 훈련 목표 >>
In this paper, we consider the coordinate of the LiDAR system as the ego car’s coordinate, and parameterize all geometric information according to it. Let 𝐒={𝐌,𝐁,𝐋} be the description of a driving scene around the ego vehicle, where 𝐌∈{0,1}𝑤×ℎ×𝑐 is the binary map representing a 𝑤×ℎ meter road area in BEV with 𝑐 semantic classes, 𝐁={(𝑐𝑖,𝑏𝑖)}𝑖=1𝑁 represents the 3D bounding box position (𝑏𝑖={(𝑥𝑗,𝑦𝑗,𝑧𝑗)}𝑗=18∈ℝ8×3) and class (𝑐𝑖∈𝒞) for each object in the scene, and 𝐋 is the text describing additional information about the scene (e.g., weather and time of day). Given a camera pose 𝐏=[𝐊,𝐑,𝐓] (i.e., intrinsics, rotation, and translation), the goal of street-view image generation is to learn a generator 𝒢(⋅) which synthesizes realistic images 𝐼∈ℝ𝐻×𝑊×3 corresponding to the scene 𝐒 and camera pose 𝐏 as, 𝐼=𝒢(𝐒,𝐏,𝑧), where 𝑧∼𝒩(0,1) is a random noise from Gaussian distribution.
또한, MagicDrive를 훈련할 때 두 가지 필수 전략을 강조
- 첫째, 보이는 상자의 필터링을 상쇄하기 위해, 무작위로 10%의 보이지 않는 상자를 증강으로 추가하여 모델의 기하학적 변환 기능을 향상시킴
- 둘째, 멀티 뷰의 근접 영상 정보 공유에 cross-view attention를 적용 시, 각 훈련 단계에서 다른 뷰에 서로 다른 특별한 노이즈를 적용함으로써 방정식 9에 대한 trivial solutions(예: 다른 보기에서 공유 구성 요소 출력)을 방지함.
- 동일한 랜덤 노이즈는 추론에만 적용됨
In this paper, our 3D geometry controls contain control from road maps, 3D object boxes, and camera poses. We do not consider others like the exact shape of objects or background contents.
<< 내 총 평 >>
이 논문에서, 저자들은 "우리의 3D 지오메트리 컨트롤은 도로 지도, 3D 객체 상자, 카메라 포즈의 컨트롤을 포함하며, 우리는 객체의 정확한 모양이나 배경 내용과 같은 다른 것을 고려하지 않습니다." 라고 하였음.
논문에서 저자들이 언급한대로,
공식 코드를 실행 해 보면,
이 논문은 도로 지도, 3d bbox, 6개의 카메라 포즈(뉴씬 데이터 기준)의 영상은 데이터 설명(뉴씬 데이터 description)에 따라,
day & night, rainny, cloudy 등의 환경의 영상을 생성하긴 하지만..
매 프레임 마다, 물체나 배경이 다르게 생성되는 현상이 있고, 차량 등의 모양도 많이 깨지는 경향이 있음
저자의 공식 코드 저장소를 봐도 되지만,
코드에 버그가 있어서, 수정한 내 저장소를 추천함
- ubuntu 20.04, nvidia A100 80GB 2장, python3.9, cuda12.1, torch==2.1.0 로 학습 & 추론 & 테스트 검증하였음
https://github.com/hyunkoome/MagicDrive
GitHub - hyunkoome/MagicDrive: [ICLR24] Official implementation of the paper “MagicDrive: Street View Generation with Diverse
[ICLR24] Official implementation of the paper “MagicDrive: Street View Generation with Diverse 3D Geometry Control” - hyunkoome/MagicDrive
github.com

위 그림처럼, detail 한 텍스트 프롬프트로 학습을 시키지 않아서인지, stable diffusion 1.5를 사용해서인지,...
저자들이 공개한 데모 영상처럼, 영상이 잘 생성되지는 않음.
'Deep Learning > 장면 스타일 변환' 카테고리의 다른 글
| MagicDriveDiT: High-Resolution Long Video Generationfor Autonomous Driving with Adaptive Control (3) | 2024.12.14 |
|---|